
replytocomをクロール禁止にしたい
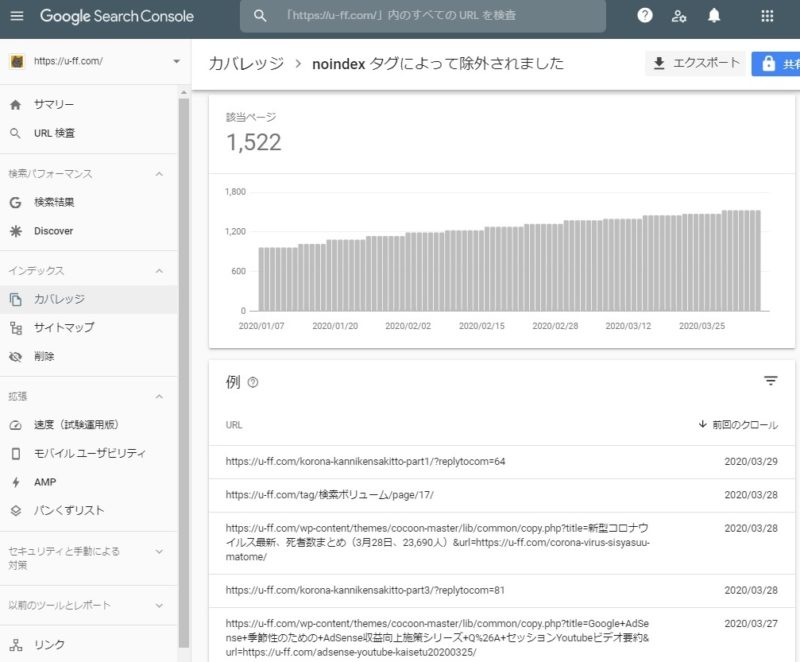
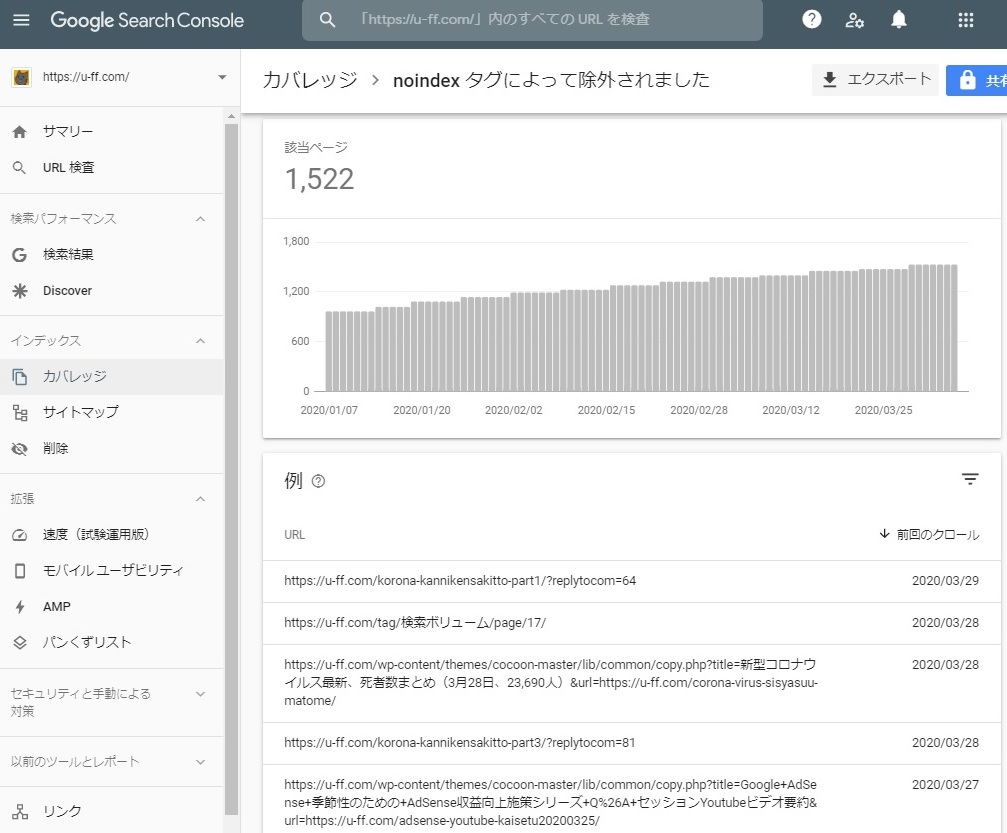
Google Search Console、noindexタグによって除外されました
Google Search Consoleで、
インデックス > カバレッジ > 除外
を確認すると、以下のようなURLが多数インデックスから除外されていました。
- ttps://u-ff.com/korona-kannikensakitto-part1/?replytocom=64
- ttps://u-ff.com/korona-kannikensakitto-part3/?replytocom=81
- ttps://u-ff.com/crawl-budget/?replytocom=162
- ttps://u-ff.com/crawl-budget/?replytocom=166
調べてみると、「replytocom」というURLパラメーターはコメントの返信先を制御するためのものでした。
以下の3つのURLはページの見た目としてはまったく同じものです。
- ttps://u-ff.com/crawl-budget/
- ttps://u-ff.com/crawl-budget/?replytocom=162
- ttps://u-ff.com/crawl-budget/?replytocom=166
Google Search Consoleから確認してみると、
- ttps://u-ff.com/crawl-budget/
上記のURLはGoogleにインデックスされているけれど、
(Googleの検索結果に表示される)
下記のURLはGoogleにインデックスされていませんでした。
(Googleの検索結果には表示されない)
- ttps://u-ff.com/crawl-budget/?replytocom=162
- ttps://u-ff.com/crawl-budget/?replytocom=166
これは正常動作です。
3つのURLでページの見た目がまったく同じなので、1つだけインデックス登録されればOKです。
むしろ、3つともインデックスされてしまうと、重複コンテンツとしてペナルティを受ける可能性があります。
replytocomがインデックス除外される流れ
replytocomはWordPressの機能です。
URLにreplytocomが含まれるページでは、自動的に
<meta name='robots' content='noindex'/>
というメタタグが挿入され、noindexの設定がされています。
noindexというのは、
「このページはGoogleの検索結果に表示しないでください」
という宣言をサイト側で設定することをいいます。
- ttps://u-ff.com/crawl-budget/?replytocom=162
上記のようなURLがGoogleの検索結果から除外されるまでの流れは以下のようになっています。
- WordPressの機能で
ttps://u-ff.com/crawl-budget/?replytocom=162
のようなページには自動的にnoindexが設定される - Googleのクローラーがこのページへクロールにやってくる
- ページの中に書かれたnoindexの設定をGoogleクローラーが検知する
- Googleの検索結果から除外される(インデックスされない)
クロールを禁止にしたい
URLにreplytocomが含まれる場合は、どうせGoogleにインデックスされません。
それならば、
「そもそもクロールをする必要すらないのでは?」
という疑問が浮かびます。
Googleにはクロールバジェットというものがあり、無駄なURLへはクロールさせないようにしたほうがいいです。
(大規模サイト以外はあまり気にしなくてもいいのですが)
クロールバジェットの話は下記をご参照ください。
「○○なページをクロール禁止にする」という設定は、
- ブログのサーバーにrobots.txtというファイルを設置する方法
- Google Search Consoleの「URLパラメータ」という機能で設定をする方法
などがあります。
今日は、
- ブログのサーバーにrobots.txtというファイルを設置する方法
の方を紹介します。
「replytocom」を例に説明をしますが、「replytocom」に限らず、同様の手順でどんなURLでもクロールを禁止にできます。
robots.txtを確認する
まずは、あなたのサイトにrobots.txtが設置済みかどうかを確認しましょう。
- 初めから自動的にrobots.txtがある場合と
- 自分で設定しないとrobots.txtが存在しない場合
があります。
このブログのトップページのURLは
- https://u-ff.com/
です。
その場合、robots.txtは
- https://u-ff.com/robots.txt
というURLになります。
上記のURLにアクセスすると、下記のようなものが表示されます。

robots.txtの見本
あなたのサイトでも、トップページの末尾に「/robots.txt」を付けたURLへアクセスしてみましょう。
上記の画像とにたようなものが表示されたら、あなたのサイトにも「robots.txt」が設定済みです。
その場合は、既にあるrobots.txtファイルに設定を書き加えていきます。
「ぺーじがありません」
「404 Not Found」
のような表示になってしまった人は、そもそもrobots.txtがサイトにありません。
自分で新しく作る必要があります。
robots.txtをダウンロードする
サイトに既にrobots.txtが存在する場合は、既存のrobots.txtをダウンロードしましょう。
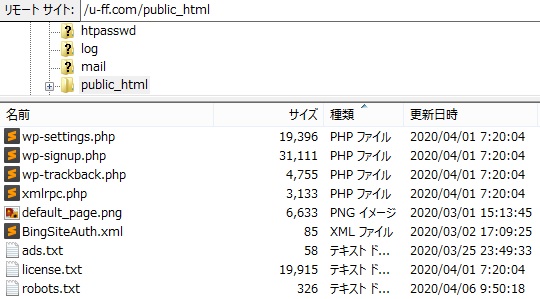
ftpでrobots.txtをダウンロードするところ
FTPソフトなどでブログのサーバーにアクセスします。
public_htmlというフォルダの下に「robots.txt」というファイルがあると思うので、それをダウンロードします。
これに設定を書き加えて、再アップロードします。
robots.txtを新しく作る
自分のサイトの
https://~~~/robots.txt
のようなURLにアクセスして、robots.txtが表示されなかった人は、新しくrobots.txtを作ります。
「メモ帳」などのテキストソフトで新しくファイルを作り、以下の内容を入力しましょう。
User-agent: * Sitemap: https://u-ff.com/sitemap.xml
※「https://u-ff.com/sitemap.xml」の部分は、自分のサイトのサイトマップのURLに変更してください。
ブログサービスではrobots.txtを変更できません
「はてなブログ」の場合は、
- https://u-ff.com/robots.txt
のようなURLにアクセスすると、robots.txtの中身が確認できると思います。
つまり、robots.txtの仕組みが採用されています。
しかし、これははてなブログ側で勝手に設定しているもので、ユーザーからは書き換えができません。
「○○をクロール禁止にしたいんだけど」
と思っても、robots.txtの中身を変更できません。
「アメーバブログ」など、その他のブログサービス系もおそらく似たような状況だと思います。
- robots.txtの仕組みがないか
- robots.txtはあるけれどブロガー側からは変更ができない
そういう制限があると思います。
robots.txtが使えるのは、レンタルサーバーを契約して、WordPressなどでブログを運営している人だけです。
(FTPなどでファイルをアップロードしたり、ダウンロードしたり、変更ができる人だけです)
robots.txtを設定する権限がない人は、Google Search Consoleの「URLパラメータ」という機能を使うと、robots.txtと似たようなことができます。
詳しくは下記の記事をご覧ください。
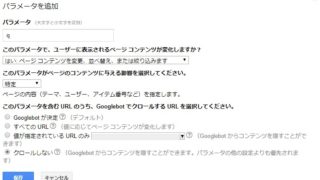
robots.txtにクロール禁止の設定を書き足す
- ttps://u-ff.com/korona-kannikensakitto-part1/?replytocom=64
- ttps://u-ff.com/korona-kannikensakitto-part3/?replytocom=81
- ttps://u-ff.com/crawl-budget/?replytocom=162
- ttps://u-ff.com/crawl-budget/?replytocom=166
上記のようなURLへのクロールを禁止にします。
条件を端的に表すと、
URLに「?replytocom=」という文字が含まれていたらクロール禁止
という設定をするのがいいでしょう。
robots.txtでは以下のように書きます。
Disallow: /*?replytocom=*
「Disallow」がクロール禁止、
「/*xxxxx*」が、URLに「xxxxx」が含まれている場合という意味です。
キーワードの前後に「*」をつけるのがポイントです。
新しくrobots.txtを作る人
User-agent: * Sitemap: https://u-ff.com/sitemap.xml
先ほど、メモ帳に上記のように入力したはずです。
ここに
Disallow: /*?replytocom=*
を書き足し、以下のようにしましょう。
User-agent: *
Disallow: /*?replytocom=*
Sitemap: https://u-ff.com/sitemap.xml
「Disallow: /*?replytocom=*」は「User-agent: *」の下の行に入れます。
既存のrobots.txtに加筆する人
サイトにもともとrobots.txtが存在していた人は、FTPなどを使って、robots.txtファイルをダウンロード済みのはずです。
これをメモ帳などで開き、
「User-agent: *」の下に
「Disallow: /*?replytocom=*」を書き加えます。
元のrobots.txt
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php Sitemap: https://u-ff.com/sitemap.xml
仮に、サイトに元々設定してあったがrobots.txtの中身が上記のようになっていたとします。
加筆後のrobots.txt
User-agent: *
Disallow: /*?replytocom=*
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://u-ff.com/sitemap.xml
「Disallow: /*?replytocom=*」を書き加えて、上記のような状態にしましょう。
ちなみに、下記のように書いてもOKです。
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Disallow: /*?replytocom=*
Sitemap: https://hagelicious.com/sitemap.xml
「User-agent: *」よりも下で、空行よりも前の一連のグループの中であれば、どの行に
「Disallow: /*?replytocom=*」を書いても構いません。
robots.txtファイルを「UTF-8」で保存する
robots.txtのファイルを保存するときに、1つだけ重要なポイントがあります。
それは、文字コード。
文字コードは「UTF-8」で保存しましょう。
「メモ帳」の場合は、普通にファイルを保存すると「SJIS」か「ANSI」になってしまいます。
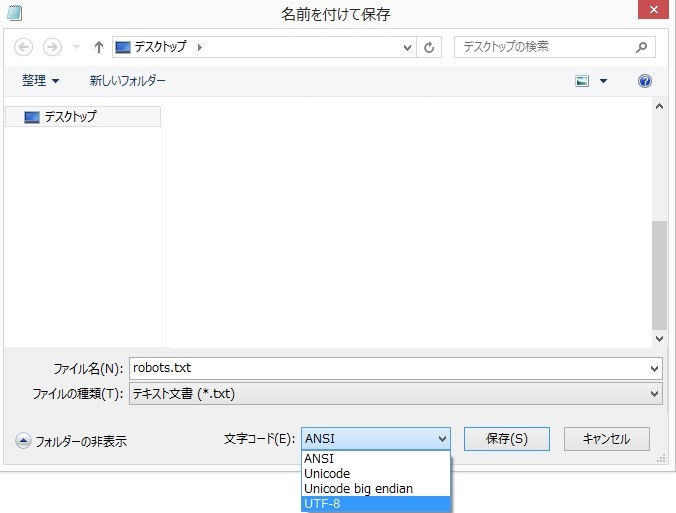
robots.txtを文字コードUTF-8で保存
「上書き保存」ではなく、「名前を付けて保存」をしましょう。
保存画面に「文字コード」という項目があるので、「UTF-8」を選びます。
「UTF-8」を選ばないと、Googleからはrobots.txtのファイルの中身が文字化けして見えてしまいます。
robots.txtをサーバーにアップロードする
ftpでrobots.txtをアップロードするところ
FTPソフトなどを使って、ブログ用のサーバーにrobots.txtファイルをアップロードします。
一般的にはpublic_htmlフォルダの下にrobots.txtを設置します。
robots.txtがアップロードされたか確認
- https://u-ff.com/robots.txt
のようなURLにアクセスして、下記のような画面になればrobots.txtのアップロードに成功しています。
URLは自分の環境に読み替えてください。
トップページの後ろに/robots.txtを付け足すだけです。
robots.txtの見本
上記の画像はただのサンプルです。
「アップロードに成功すると、「User-Agent: is_archiver」みたいな行が自動的に表示される」という話ではないのでご留意ください。
robots.txtの中身は、robots.txtをメモ帳で見たときと、URLにアクセスして見たときで同じになっていればOKです。
サイト内検索をクロール禁止にする
- ttps://u-ff.com/search-result/?q=adsense
- ttps://u-ff.com/search-result/?q=ブログ
このブログの場合は、サイト内検索をすると、検索結果ページが上記のようなURLで開きます。
キーワードの数だけ無限にURLのパターンが発生してしまいます。
こういう場合は、クロール禁止にした方がいいでしょう。
クロールを禁止しておかないと、無限にクロールバジェットが消費される危険があります。
robots.txtで禁止する場合、以下の2通りのやり方があります。
- パラメーターで禁止
- パスで禁止
URLパラメーターqをクロール禁止にする
「replytocom」のときの話にならい、
URLに「?q=」が含まれている場合はクロール禁止
という設定をしてみましょう。
User-agent: *
Disallow: /*?q=*
Disallow: /*?replytocom=*
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://u-ff.com/sitemap.xml
robots.txtの中身を上記のように書いて、サーバーにアップロードすればOKです。
Disallow: /*?q=*
という行を書き足しました。
/search-result /をクロール禁止にする
- ttps://u-ff.com/search-result/?q=adsense
- ttps://u-ff.com/search-result/?q=ブログ
上記のURLはどちらも/search-result/というパスが含まれています。
- ttps://u-ff.com/search-result/
上記のURLにアクセスしても、本文になにもない空の検索結果ページが表示されます。
それならば、URLパラメーターの「q」を使わずに
- ttps://u-ff.com/search-result/
というページそのものをクロールの対象から外すことも考えられます。
その場合は、robots.txtを以下のように書きます。
User-agent: *
Disallow: /search-result/
Disallow: /search-result$
Disallow: /*?replytocom=*
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://u-ff.com/sitemap.xml
以下のような1行をrobots.txtに書くことで
Disallow: /search-result/
- ttps://u-ff.com/search-result/
というURLに対してクロールを禁止にできます。
ただし、
- ttps://u-ff.com/search-result
(末尾のスラッシュがない)
というURLはスルーされてしまいます。
そのため、
Disallow: /search-result$
という1行をrobots.txtに書くことで
- ttps://u-ff.com/search-result
に対してもクロール禁止にしています。
「$」はURLの末尾を表します。
(resultのtの後ろには何も続かないという意味)
Googleがrobots.txtを無視することがある
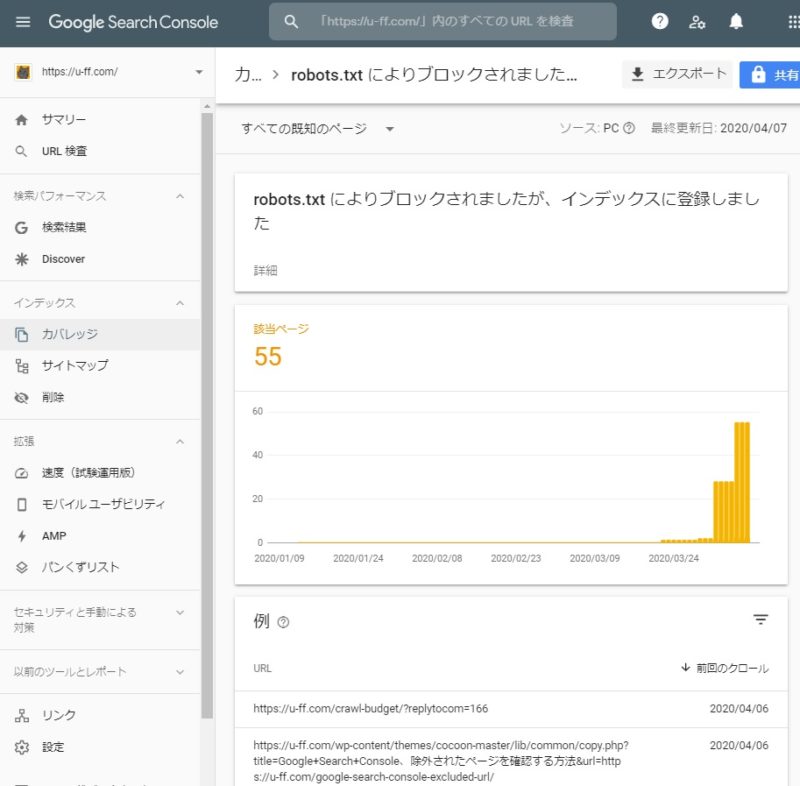
Google Search Console、robots.txtによりブロックされましたが、インデックスに登録しました
robots.txtに設定を追加し、「replytocm」を含むURLはクロールしないようにブロックしました。
その結果どうなったかというと……
Google Search Consoleに
「robots.txt によりブロックされましたが、インデックスに登録しました」
という警告が表示されました。
ここまで読んで下さった方には申し訳ないのですが、今回の作業は大失敗ですね。
「robots.txt によりブロックされましたが」
とあるように、robots.txtの設定自体はうまくいっています。
Google側も、
- ttps://u-ff.com/crawl-budget/?replytocom=166
というURLがブロックされていることには気づいています。
それなのに、Googleさんは
「ブロック」の設定を無視して、
「インデックに登録しといたよ」とおっしゃっています。
Googleさん、ブロックに気づいているなら、インデックスしないでくださいよ……
まとめ
robots.txtに
Disallow: /~~~~~
上記のようなものを書くことで、そのURLへのクロールを禁止にできます。
(~~~~~の部分にはクロール禁止にしたいURLの条件を書きます)
robots.txtを使うには、サーバー上のファイルを編集する権限が必要です。
そのため、「はてなブログ」「アメーバブログ」などのブログサービス系ではrobots.txtは使えません。
robots.txtでクロールを禁止にしても、Googleがそれを無視することがあります。
Googleがrobots.txtを無視する話は、下記に詳しく説明があります。
コメント