
Googleがrobots.txtを無視する
robots.txtというファイルをブログに設置すると、特定のURLをGoogleがクロールしないように制御できます。
- ttps://u-ff.com/korona-kannikensakitto-part1/?replytocom=64
- ttps://u-ff.com/korona-kannikensakitto-part3/?replytocom=81
- ttps://u-ff.com/crawl-budget/?replytocom=162
- ttps://u-ff.com/crawl-budget/?replytocom=166
上記のようなURLへクロールしてほしくなかったので、robots.txtに
Disallow: /*?replytocom=*
という設定を追加しました。
詳しい設定手順は下記をご参照ください。
これで、URLに「?replytocom=」が含まれるURLに対してはクロールをしなくなるはず。
しかし、ここで問題が発生。
Googleさんが、
- クロールはしないけど、インデックスはする
という予想外の動きをしやがりました。
クロールを禁止にしたのは、インデックスをして欲しくないからなんですが…
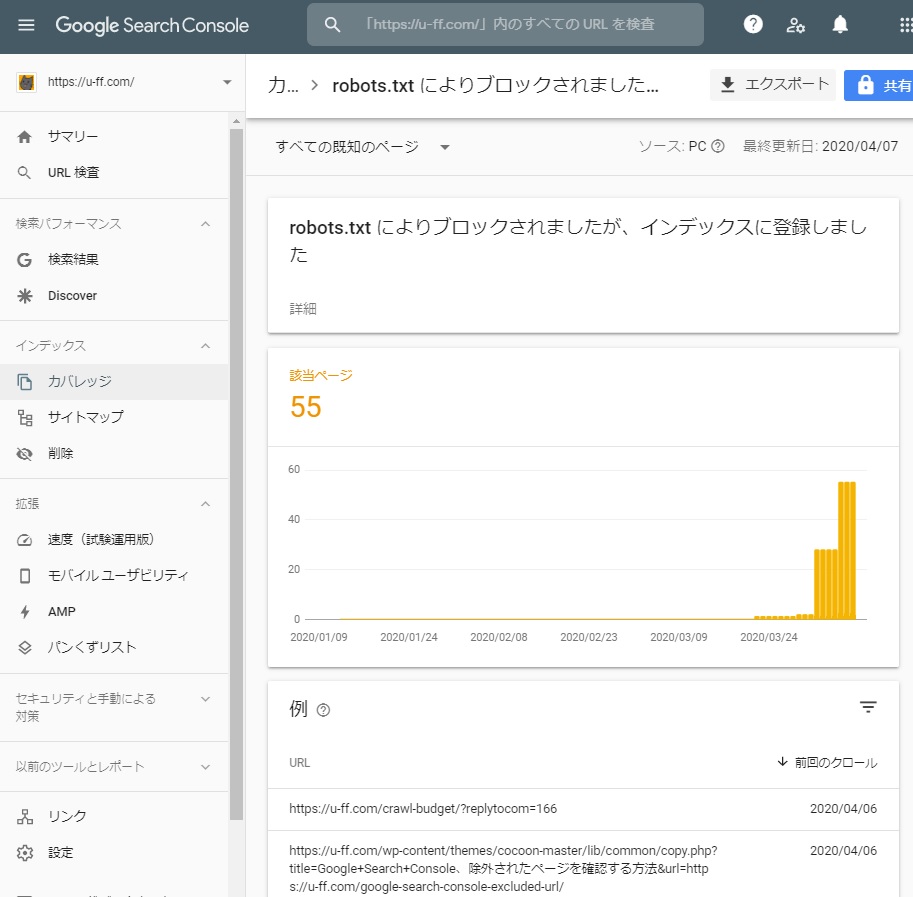
robots.txt によりブロックされましたが、インデックスに登録しました
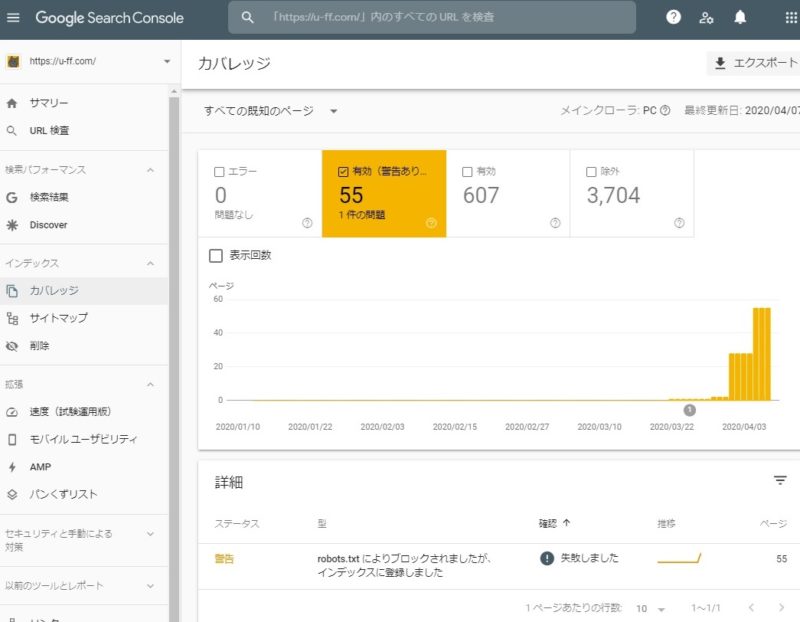
Google Search Console、インデックス > カバレッジ > 有効(警告あり)
Google Search Consoleの管理画面で、
インデックス > カバレッジ > 有効(警告あり)
の画面を開くと、
「robots.txt によりブロックされましたが、インデックスに登録しました」
というものが多数出現しました。
「robots.txt によりブロックされましたが、インデックスに登録しました」
の部分をクリックすると、以下のような画面になります。
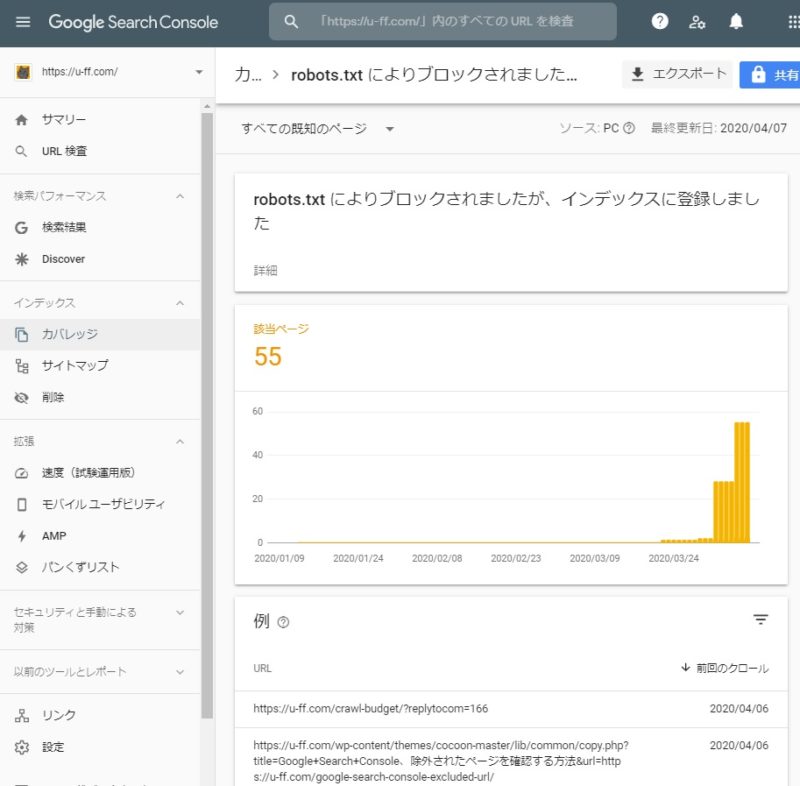
Google Search Console、robots.txtによりブロックされましたが、インデックスに登録しました
- ttps://u-ff.com/crawl-budget/?replytocom=166
上記のようなURLがここに分類されています。
「robots.txt によりブロックされましたが、インデックスに登録しました」
とのことなので、robots.txtでクロールをブロックするのには成功しています。
robots.txtの設定が間違っているわけではありません。
しかし、ブロックしたにもかかわらずインデックスには登録されてしまいました。
Googleで検索結果を確かめる
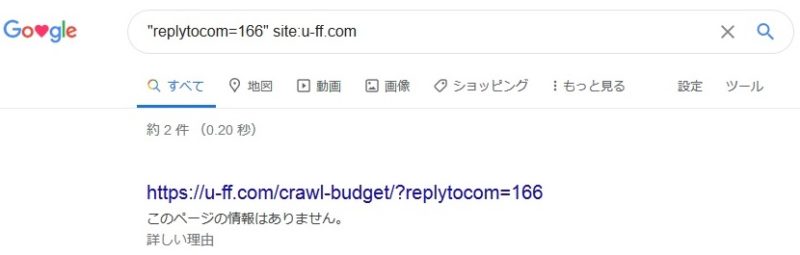
Google検索結果、replytocomで検索
Googleで、”replytocom=166″を検索してみたところ、
- ttps://u-ff.com/crawl-budget/?replytocom=166
が検索結果に表示されました。
本来は記事のタイトルが表示されるべきところに
「ttps://u-ff.com/crawl-budget/?replytocom=166」
と表示されています。
そして、本文の概要が表示されるべきところに
「このページの情報はありません。」
と表示されています。
robots.txtでクロールを禁止にしたので、記事のタイトルや本文を取得できなかったのでしょう。
つまり、Googleはクロールをしていない。
robots.txtの設定は、ある意味成功しています。
しかし、
- クロールはしない、インデックスもしない
を期待していたのに
- クロールはしない、インデックスはする
という予想外の状態になってしまいました。
Googleはリンクを勝手にインデックス登録する
上記の記事の下の方にコメント欄があります。
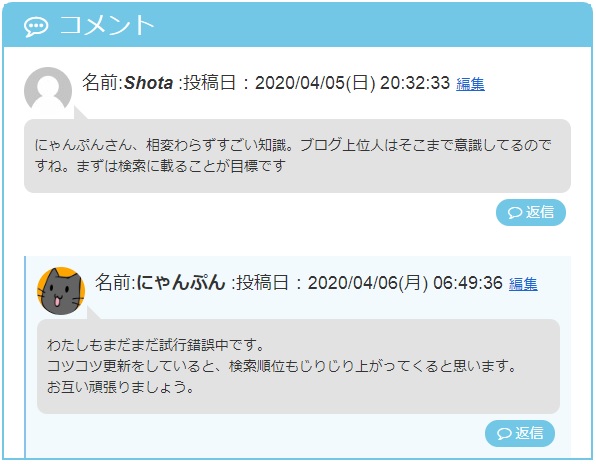
ブログのコメント返信にはreplytocomへのURLがリンクされている
Shotaさんのコメントの下にある「返信」というボタンには
- ttps://u-ff.com/crawl-budget/?replytocom=162#respond
というURLへのリンクが貼られています。
にゃんぷんのコメントの下にある「返信」というボタンには
- ttps://u-ff.com/crawl-budget/?replytocom=166#respond
というURLへのリンクが貼られています。
調べてみたところ、Googleさんには
「リンクが貼られていたら、とりあえずインデックスに登録する」
という癖があるらしいです。
- ttps://u-ff.com/crawl-budget/?replytocom=162
- ttps://u-ff.com/crawl-budget/?replytocom=166
などのURLは、robots.txtの設定でクロールを禁止してあります。
そのため、Googlebotとしては
「リンクが貼られていたのでインデックス登録しといたよ。
だけどrobots.txtでクロール禁止だったから、タイトルや本文は取得しなかったよ」
という動きをしているようです。
robots.txtでのクロール禁止を解除する
robots.txtでクロール禁止中
robots.txtに
Disallow: /*?replytocom=*
という設定をした結果、以下のような現象が発生しました。
- Googleがクロールを試みる
- robots.txtでクロール禁止なっているので、実際にはGoogleはページをクロールしない
(タイトルや本文は取得できない) - だけどインデックスはする
(どこかのページからreplytocomを含むURLへのリンクが貼られているせい) - Google検索結果にタイトルも概要もない、URLだけの謎のアイテムが表示されるようになる
Googleはタイトルも本文も取得できていません。
そのため、一般人が普通のキーワードで検索した場合に、検索結果の一覧にreplytocomのページが登場することはないと思われます。
しかし、謎のアイテムとしてインデックスに残るのは好ましくない気がします。
robots.txtでクロールを許可
robots.txtから以下の設定を削除しました。
Disallow: /*?replytocom=*
すると、以下の状態になります(仮)。
- Googleがクロールする
- インデックスされる
- Google検索結果にタイトルも概要も含む、普通のアイテムが表示される
ただし、WordPressの機能で、replytocomのページには以下のようなメタタグが設定してあります。
<meta name='robots' content='noindex'/>
そのため、実際には以下の状態になります。
- Googleがクロールする
- Googlebotがページの中にnoindexの設定を見つける
- インデックスされない
- Google検索結果には表示されない
robots.txtの設定で何が起こるか?
URLにreplytocomを含むページに対して
- クロールはしない、インデックスもしない
を目指していました。
しかし、robots.txtでクロールを禁止にした結果、
- クロールはしない、インデックスはする
という状態になってしまいました。
そこで、robots.txtの設定を解除したら以下の状態になりました。
- クロールはする、インデックスはしない
URLにreplytocomを含むページはインデックスをしてほしくありません。
robots.txtでクロールを禁止するのは失敗でした。
結局は、
「あえてクロールをさせることで、noindexの設定を明確にGooglebotに読み込ませる」
というのが確実にインデックスを禁止にするコツのようです。
インデックス > カバレッジ > 除外
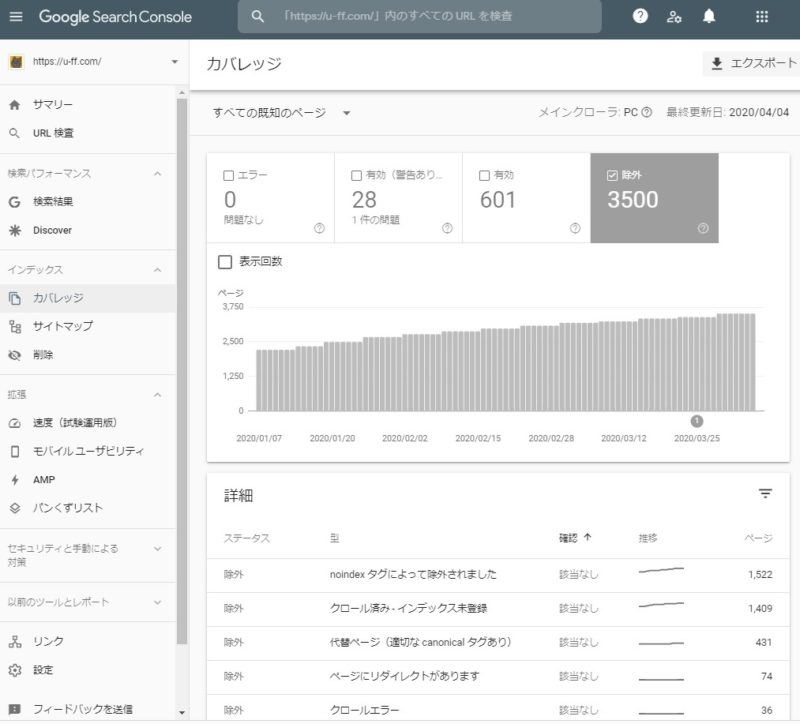
Google Search Console、インデックス > カバレッジ > 除外
robots.txtでクロール禁止の設定を解除した結果、
- ttps://u-ff.com/crawl-budget/?replytocom=162
のようなURLは、Google Search Consoleの管理画面で
インデックス > カバレッジ > 除外
「noindex タグによって除外されました」
に分類されるようになりました。
「robots.txt によりブロックされましたが、インデックスに登録しました」よりは、
「noindex タグによって除外されました」の方が望ましいです。
robots.txt設定前後の顛末をおさらい
| noindex設定なし | noindex設定あり | |
|---|---|---|
| robots.txtで クロール禁止なし |
① インデックスされる |
② インデックスされない |
| robots.txtで クロール禁止あり |
③ インデックスされる |
④ インデックスされる |
普通のページは、
「①クロール禁止なし、noindexなし」=「インデックスされる」
の状態です。
今回、試行錯誤の対象となった「replytocom」のページは
「②クロール禁止なし、noindexあり」=「インデックスされない」
の状態でした。
robots.txtでクロール禁止にした結果
「④クロール禁止あり、noindexあり」=「インデックスされる」
という状態になってしまいました。
そこで、robots.txtの設定を元に戻し
「②クロール禁止なし、noindexあり」=「インデックスされない」
の状態に戻しました。
まとめ
クロールバジェット節約のために、特定のURLに対してクロールを禁止にしようとしました。
しかし、Googleは
「クロール禁止でも、とりあえずインデック登録する」
という動きをするようです。
そのため、クロール禁止&インデックス禁止は無理でした。
Googleの検索結果に表示したくないページがある場合は、
robots.txtによる「クロール禁止」を設定するのはよくないようです。
インデックスに登録したくないページには、メタタグ等を使ってnoindexを設定しましょう。
ちなみに、robots.txtはGoogle以外のものにも影響します。
人のサイトを丸ごとコピーする、いわゆる魚拓サイトに対して、コピー禁止を宣言するときに使ったりします。
そのため、robots.txtがまったくの無意味という訳ではないです。
ブロガーの教養として、robots.txtの使い方は覚えておいたほうがいいでしょう。
また、noindexの設定は、metaタグを使う以外にも、X-Robots-Tagを使う方法もあります。
metaタグはHTMLで使えますが、XMLでは使えません。
サイトマップやRSSなんかはXMLなので、noindexにしたかったらX-Robots-Tagを使います。
次回は、X-Robots-Tagでnoindexを設定する方法を紹介します。
コメント